

AI is not coming for your job

From the beginning, the current AI boom has been characterized by one sentiment: it’s never been more over. For knowledge workers, there is palpable terror that intelligence too cheap to meter will shortly make every laptop jockey across the world unemployable as a matter of simple economics. Forget third-world sweatshops hollowing out the American manufacturing base, the true threat was always the one that Ned Ludd warned us about: automation making humans obsolete. And unlike the weavers of the 19th century, there will be no ladder of prosperity into the service economy for the human redundancies to climb. This is it, the final obsolescence for any member of the proletariat selling keystrokes for their daily bread.
Total balderdash. Generative LLMs will soon reach a point of undeniably diminishing returns and become just another algorithmic tool that we no longer refer to as “artificial intelligence”, just like we did for chess solvers, speech recognition, image classifiers, etc. A decade from now we’ll refer to these systems by their proper names: code generators, chat bots, automatic writers, speech-to-image. What we won’t call them is intelligent.
The limitations of LLMs
I spent twenty minutes writing a primer on how LLMs work before realizing it’s a distraction from the point I’m arguing and throwing it away. You probably are already familiar with the basics of the tech, and if not there are much better explainers out there than the one I was writing. For now look at this image and be reassured that the author is technically proficient enough to grasp what the tech is and how it works.

Here’s what matters: you train a neural net by showing it a great deal of examples with the answers attached, each of which contributes in some minute way to the statistical weights in the network. That’s how a neural net classifier (which we mostly don’t call AI anymore) works. Generative AI is basically a classifier run in reverse, kind of like Jeopardy! — here’s the answer, now tell me the question. There are lots of details I’m omitting and AI researchers reading this are getting mad, but that’s the basic idea.
What’s more interesting is observing how the technology operates in practice.

Why does it make this dumb error? The LLM, having been exposed to tens of thousands of examples of the gotcha woman-doctor riddle on various web sites, has over-indexed on it. Even when you directly give it the answer to the non-riddle, it can’t help but pattern-match it to the riddle and generate the above nonsense.
Here’s another example of a “classic riddle” with a twist that invalidates it. The LLM (4o again) pattern-matches instead of realizing the riddle cannot be solved with the additional “cabbage can’t be with lion” constraint, and produces obvious nonsense.
But even when the task is to generate a pattern, advanced LLMs screw up when precision matters. Here is Open AI’s o3 model falling on its face when asked to keep track of a number less than 30.

AI boosters say that these are growing pains, and the problems can be solved by shoveling an even larger percentage of GDP at Nvidia. After all, we’ve seen massive performance gains in specific targeted tasks, like multiplying numbers. Just a few months separate these two results:


I don’t want to downplay this result from the Allen Institute, which is genuinely impressive in what it achieves. But it should also be obvious that 99.7% accuracy at a completely determinate task is unacceptable for most domains in which it might be used. Even after explicitly training the model how to perform multidigit multiplication in a grind of iterations, it still gets the wrong answer 3 times in a thousand. Hope you’re not on that flight!
But what’s even more damning is the fact that the model had to be trained on the multiplication algorithm in the first place. You know the one, it looks like this:

A truly intelligent model that has memorized its times table from 0 to 9 (trivial, and it has) and can add any two single digits together (trivial, and it can) and can recite the steps of the algorithm (it can) should be able to apply it to any number of digits, because the algorithm generalizes to any number of digits. But it can’t, not without the specialized iterative reinforcement for the task that the Allen Institute demonstrated above.
The reason this is so, and the reason they are so easily tripped up by fake gotcha riddle questions, is because these models can’t reason. What do I mean by reasoning? Simply: the ability to combine knowledge, analysis, and logic to solve novel problems. LLMs produce a somewhat convincing facsimile of reasoning that breaks down when you poke it the wrong way because it’s fake. It’s pattern matching in reverse. The fact that many problems which appear at first glance to require reasoning can actually be solved by sufficiently complicated stochastic pattern matching is surprising to me personally, but if you’ve ever worked with a not-very-bright programmer who nevertheless got things more-or-less working by copying and pasting stack overflow examples, you start to understand how this can be so.
What about the scaling
I already mentioned the obvious objection to my skepticism earlier: these are just growing pains, and will go away when the digital brains get big enough. Believers point to model performance on various benchmarks, which are improving at an impressive and growing rate.
My counter-objection is even simpler though: these models are already trained on a non-trivial fraction of all information ever created. GPT3 was trained on around 570 GB of plain text, mostly from crawling the internet and digitizing books. Microsoft Copilot consumed every public code repository on GitHub. Sure, there are more words and more code out there that could be fed to the machines. But why would we expect it to make a dramatic difference on top of the literal billions of words and lines of code already used in its training?
Yes, these models are still getting better, and by some metrics they are accelerating. But nobody really knows if this growth has a natural limit or can go on indefinitely. At this phase in the growth cycle, it’s very easy to mistake a logistical curve for an exponential one.

Again: nobody commenting on these topics knows whether the growth in capability we’re observing now has a natural carrying capacity or can go on forever, or where that carrying capacity might be if it exists. Using a naturalist metaphor, we know for certain there is a finite number of prey to be consumed — all the words and all the lines of code ever written, all the artwork scanned and uploaded. True believers assert that some combination of more powerful hardware and more clever algorithmic techniques will overcome the finite amount of data to train on, that sufficiently powerful wolves will grow to the size of the solar system and travel at the speed of light despite having a finite number of sheep to consume. I can’t prove them wrong, but color me skeptical.
The robots are not coming for your job or your life
Many of the prominent commentators asserting otherwise have spent the last 25 years stewing in an intellectual movement that asserts machine superintelligence is inevitable due to the continued expansion in hardware capability described by Moore’s Law. Here’s a chart by Ray Kurzweil from shortly after the turn of the century showing that the amount of processing power you can buy for $1000 should pass a human brain by the mid 2020s and all human brains by the 2050s.
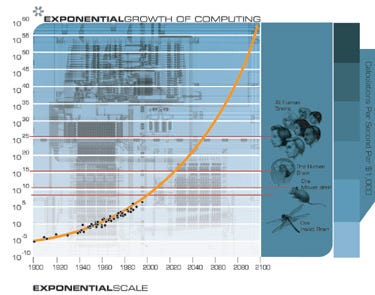
Kurzweil is maybe the largest single figure in this movement, which focuses on an idea called The Singularity: a technological event horizon after which you cannot extrapolate the future from current events because the pace of change becomes too rapid and therefore too chaotic to reason about.
Notably, the Singularitarians mostly endorsed a timeline with machine superintelligence arising sometime in the first half of the century before LLMs or any other plausible architecture for machine intelligence was demonstrated. When I was last closely tracking this scene around 2008 or so, the dominant meme was brain simulation via connectome-scanning (which caused more people than you might expect to make deals to freeze and store their heads upon their deaths). But they weren’t sure exactly how superintelligence would arise, only that it would happen, somehow, some way, based on the extrapolations in hardware power like in the chart above. They considered it inevitable. Then ChatGPT hit the scene and all the same dorks proclaimed the nativity of the infant machine god, the digital messiah written about in the scriptures. They were so certain about this that prominent thought-leaders called on the US government to bomb data centers, just in case.
Shut down all the large GPU clusters (the large computer farms where the most powerful AIs are refined). Shut down all the large training runs. Put a ceiling on how much computing power anyone is allowed to use in training an AI system, and move it downward over the coming years to compensate for more efficient training algorithms. No exceptions for governments and militaries. Make immediate multinational agreements to prevent the prohibited activities from moving elsewhere. Track all GPUs sold. If intelligence says that a country outside the agreement is building a GPU cluster, be less scared of a shooting conflict between nations than of the moratorium being violated; be willing to destroy a rogue datacenter by airstrike.
Seems to me that a lot of you nerds are forgetting the first two rules of Singularity Club: you can’t reason about the events after the technological event horizon. And speaking of predicting events, Kurzweil himself made a lot of specific, testable predictions with dates attached that have mostly not come true.
Nevertheless, we’ve been treated to a breathless stream of predictions about the shape of what’s to come, most recently with alpha nerd Scott Alexander endorsing a timeline that looks like this:
2027: no more entry-level programming jobs
2028: fully AI-managed robot economy
2030: humans wiped out by robots
This is, in a word, nuts. These predictions rely on AI tools advancing not just from human innovation and hardware improvements, but in a cycle of faster-than-human self-improvement that remains strictly speculative. They rely on effectively simulated agency — forget debates about reasoning and intelligence, agency is the easy thing we can say with certainty LLMs don’t have. And they predict this all coming to pass inside of three years. This should go without saying, but if your methodology and worldview leads you to fantastical conclusions no matter how many times you check your math, you should take it as a strong indication that your methodology and worldview are wrong, not that it’s time to start gassing up the drones for datacenter strikes.
The robots are our friends
I use AI tools every day. They write a majority of my code for me. This is what it’s good at: looking at the extremely formulaic structure of computer code and producing a plausible guess at what should come next. It guesses right, or close enough to right, often enough to save me a lot of effort. The phrase is becoming cliché already, but it’s true that these tools are glorified auto-complete. This isn’t an insult — autocomplete is a godsend, and LLM tech radically increases its utility. It lets me get a lot more done, and that’s a good thing.
But I’m also aware of what it’s not. It’s not a substitute for human judgement. It’s terrible at true originality and ideation, hopeless at analysis and design outside of well-worn patterns. It can’t experiment and iterate to save its life. It’s good at greenfield development, generating output from whole cloth, but remarkably bad at integrating what came before and expanding upon it. Not only is Devin vaporware, the vibe coders larping as him via Cursor are creating world-class messes they don’t understand that the tool can’t fix for them. Like a novice programmer, their power to generate code far exceeds their ability to understand or maintain it as it grows.
None of this is to write off the obvious utility of AI tools. Knowledge workers will see a large boost to their productivity by using them, just as they did from adopting the word processor, the spreadsheet, photoshop, CAD, and Salesforce. The robots are wonderful servants, and in time we’ll wonder how we ever got by without them.
But knowledge workers won’t be replaced by our tools, or at least not by these ones. LLMs aren’t capable of true intelligence, reasoning or agency the way a human is. They’ll need their human benefactors to hold their hands and verify every little task, now and in the future. And we should be thankful they’re here to help, not fearful they’ll replace us.
And the best part of adopting this outlook — if it’s wrong, it doesn’t matter at all. Because we’re all dead anyway.
I agree within the kind of jobs you’re talking about. But I already see it taking over jobs in other domains. For example, AI is good at photo editing. REALLY good at it. Me with my iPhone 15 Pro and AI (and admittedly some hobby photography knowhow) can produce results that used to require a lot of equipment and training. If I had the money, I would have paid for Christmas mini shoots, for example. And now I won’t even consider it. Maybe it doesn’t rise to full pro quality. But it’s good enough that I would rather pay $0 than $300 and eat the quality difference. I don’t know what other jobs have this characteristic, but I expect the employment opportunities for your run of the mill family photographers will shrink rapidly once more people figure this out. I think very gifted photographers will be fine. But your garden variety photographers that produce more generic work will find a lot less demand for their skills. There will be no room in that field for your average kid who just wants to take pictures for a living. Which is a shame from a certain point of view (although I know a subset of AI theorists who don’t care if mediocre creative people should get to do something they love for pay). Because I know a mediocre photographer who is extraordinarily dedicated to the job.
The risk isn't that AI is going to take away jobs, but it will be so intrusive and stifling through its implementation in Social Media, banking, transportation, human resources, etc. that it will destroy all ability for human agency outside of scenarios it can handle. Gotta be safe, dontchaknow. It will become a straitjacket over all mankind.
Butlerian Jihad now.